























Originally published September 1, 2021 @ 6:25 pm
Some Linux CLI commands I type every day, probably hundreds of times. Others – on a rare occasion. But there’s a category of truly esoteric utilities tailor-made for some singular and often exotic purpose. I heard of many – if not most – of these utilities, but it’s difficult to recall their names in those unlikely circumstances when I could’ve used these tools. And that’s the reason for this short write-up.
Many of these programs come from the Linux moreutils package. It is usually not installed by default in most distros but is almost always available from the official repo.
chronic
This straightforward utility helps you declutter crontab by replacing the common >/dev/null 2>&1 redirect construct at the end of each cronjob. Not a huge deal, but it certainly makes things easier to read.
chronic runs a command, and arranges for its standard out and standard error to only be displayed if the command fails (exits nonzero or crashes). If the command succeeds, any extraneous output will be hidden. A common use for chronic is for running a cron job. Rather than trying to keep the command quiet, and having to deal with mails containing accidental output when it succeeds, and not verbose enough output when it fails, you can just run it verbosely always, and use chronic to hide the successful output. 0 1 * * * chronic backup # instead of backup >/dev/null 2>&1 */20 * * * * chronic -ve my_script # verbose for debugging
'chronic' man page
combine
This is a very useful utility that uses logical operators to compare lines in two text files.
combine combines the lines in two files. Depending on the boolean operation specified, the contents will be combined in different ways: and Outputs lines that are in file1 if they are also present in file2. not Outputs lines that are in file1 but not in file2. or Outputs lines that are in file1 or file2. xor Outputs lines that are in either file1 or file2, but not in both files.'combine' man page
Consider the following example:
| file1 | file2 |
1 2 3 4 5 | 2 3 6 5 5 |
for i in and not or xor; do echo -en "$i:\t"; combine file1 $i file2 | xargs; done and: 2 3 5 not: 1 4 or: 1 2 3 4 5 2 3 6 5 5 xor: 1 4 6
Accomplishing the same task without the combine utility would require quite a bit more effort. For example:
# Equivalent to the 'not' operator above
diff --new-line-format="" --unchanged-line-format="" <(sort -u file1) <(sort -u file2) | xargs
1 4
# Equivalent to the 'and' operator above
awk 'FNR==NR{a[$1];next}($1 in a){print}' file2 file1 | xargs
2 3 5
errno
You can put errno in your scripts to use proper error codes and provide more meaningful error messages. This will make it easier to debug your scripts.
errno looks up errno macro names, errno codes, and the corresponding descriptions. For example, if given ENOENT on a Linux system, it prints out the code 2 and the description "No such file or directory". If given the code 2, it prints ENOENT and the same description.
'errno' man page
Here’s a quick example:
[ -f /tmp/no_such_file ] || errno 2 ENOENT 2 No such file or directory
ifdata
This utility shows you various information about the network interfaces on your system. While you can obtain the same data using more common tools like ethtool or ifconfig, ifdata has the ability to extract just a single parameter. This is very useful in scripting as it saves you the need to parse the complex and often inconsistent output of ifconfig and such.
ifdata can be used to check for the existence of a network interface, or to get information abut the interface, such as its IP address. Unlike ifconfig or ip, ifdata has simple to parse output that is designed to be easily used by a shell script.
'ifdata' man page
In the following example, we will use ifdata to print out a NIC’s address, netmask, broadcast address, MTU, and MAC address:
for i in a n b m h; do ifdata -p$i bond0; done | xargs 192.168.122.137 255.255.255.0 192.168.122.255 1500 A0:48:1C:B8:17:B8
Just extracting the IP address from the ifconfig output would’ve required a whole lot more typing:
ifconfig bond0 | sed -rn 's/127.0.0.1//;s/.*inet (addr:)?(([0-9]*\.){3}[0-9]*).*//p'
192.168.122.137
ifne
This utility will execute any command that follows it but only if the standard input was not null. Simple but saves you some typing.
ifne runs the following command if and only if the standard input is not empty.
'ifne' man page
In the example below I am grepping for some common error keywords in the syslog file and sending myself an email containing any matched lines.
egrep -i "error|fail|fatal" /var/log/messages | ifne mailx -s "error log" root@jedi.local
To accomplish the same without the ifne command, you will need to assign the output of grep to a variable and then check if the variable is empty:
body=$(egrep -i "error|fail|fatal" /var/log/messages); [[ -n "$body" ]] && mailx -s "error log" root@jedi.local <<<"$body"
isutf8
Non-UTF-8 characters in scripts can be a real headache. This happens often when people copy-paste code from poorly-formatted sources, such as Word documents and emails.
isutf8 checks whether files are syntactically valid UTF-8. Input is either files named on the command line, or the standard input. Notices about files with invalid UTF-8 are printed to standard output.
'isutf8' man page
In this example I am looking for Python scripts containing non-UTF-8 characters:
find /usr/lib -name '*.py' | xargs isutf8
Alternative methods are uninformative and CPU-intensive:
# This is reasonably quick and tells you the line number, but doesn't show the actual non-UTF-8 characters
find /usr/lib -name '*.py' | xargs grep -naxv '.*'
# This is much slower and will only show you the file name, but more reliable than the 'grep' example above
find /usr/lib -name '*.py' | xargs -I {} bash -c "iconv -f utf-8 -t utf-16 {} &>/dev/null || echo {}"
flock
This command replaces a similar older utility called lckdo. The flock command is often used to prevent multiple instances of the same script from running concurrently. This can be very useful for cron jobs, among other applications.
This utility manages flock(2) locks from within shell scripts or from the command line.
'flock' man page
# Cron will execute the job every minute, but the script will only run if # the lock file does not exist. * * * * * /usr/bin/flock -n /tmp/.your_script.lock /root/your_script.sh
A common alternative to this method is to create a PID file from within the script itself. For example:
PIDFILE="/tmp/$(basename $0).pid"
if [ -f "${PIDFILE}" ]; then
if ps -p $(cat "${PIDFILE}") >/dev/null 2>&1; then
echo "$0 is already running!"
exit
fi
fi
echo $$ > "${PIDFILE}"
trap '/bin/rm -f "${PIDFILE}" >/dev/null 2>&1' EXIT HUP KILL INT QUIT TERM
mispipe
This utility allows you to pipe two commands and the get exit status of the first command, rather than the second one. This seemingly basic feature can be invaluable in certain situations.
mispipe pipes two commands together like the shell does, but unlike piping in the shell, which returns the exit status of the last command; when using mispipe, the exit status of the first command is returned.
'mispipe' man page
Here I am trying to count the number of active entries in /etc/hosts, except that I misspelled the name of the file. You can see how the exit status changes depending on how I pipe the two commands:
# Using 'mispipe' returns an appropriate error code mispipe "grep -Pv '^[[:alnum:]]' /etc/hostss 2>/dev/null" "wc -c 2>/dev/null 1>&2"; errno $? ENOENT 2 No such file or directory # Using the standard pipe returns no error grep -Pv '^[[:alnum:]]' /etc/hostss 2>/dev/null | wc -c 2>/dev/null 1>&2; errno $?
An alternative way is to use the Bash PIPESTATUS array variable that contains the exit codes from the most recent foreground pipeline. For example:
grep -Pv '^[[:alnum:]]' /etc/hostss 2>/dev/null | wc -c 2>/dev/null 1>&2; echo "${PIPESTATUS[0]} ${PIPESTATUS[1]}"
2 0
parallel
This application is a far more sophisticated alternative to xargs as it allows you to combine multiple input sources, select from a variety of input linking arguments, distribute the workload across multiple networked computers, and much more.
GNU parallel is a shell tool for executing jobs in parallel using one or more computers. A job can be a single command or a small script that has to be run for each of the lines in the input. The typical input is a list of files, a list of hosts, a list of users, a list of URLs, or a list of tables. A job can also be a command that reads from a pipe. GNU parallel can then split the input into blocks and pipe a block into each command in parallel.
'parallel' man page
In this example, I will rsync a bunch of files from one directory to another using parallel to spawn a separate transfer thread for each file. This can greatly improve copy speed when dealing with a bunch of small files on an NFS mount.
The first step is to generate some sample data for the rsync.
# created 110200 files in 11111 folders - a total of about 1.7GB
for i in `seq 1 10`; do
echo "Top level $i"
for j in `seq 1 10`; do
for k in `seq 1 10`; do
for l in `seq 1 10`; do
mkdir -p /archive/source/dir_${i}/dir_${j}/dir_${k}/dir_${l}
for n in `seq 1 10`; do
dd if=/dev/zero of=/archive/source/dir_${i}/dir_${j}/dir_${k}/dir_${l}/${RANDOM}_${RANDOM}.txt bs=16K count=1 >/dev/null 2>&1 ; done; done
for n in `seq 1 10`; do
dd if=/dev/zero of=/archive/source/dir_${i}/dir_${j}/dir_${k}/${RANDOM}_${RANDOM}.txt bs=16K count=1 >/dev/null 2>&1 ; done; done
for n in `seq 1 10`; do
dd if=/dev/zero of=/archive/source/dir_${i}/dir_${l}/${RANDOM}_${RANDOM}.txt bs=16K count=1 >/dev/null 2>&1 ; done; done
for n in `seq 1 10`; do
dd if=/dev/zero of=/archive/source/dir_${i}/${RANDOM}_${RANDOM}.txt bs=16K count=1 >/dev/null 2>&1 ; done; done
Now we can try using parallel to kick off a separate rsync thread for each subfolder under /archive/source/. Note that I am limiting the number of concurrent processes to 8, which is the number of CPU cores I have on my test server:
ls /archive/source| parallel --gnu --no-notice -j 8 'rsync -aKxq "/archive/source/{}" /archive/target/'
Now I will delete /archive/target and rerun the sync operation once more using xargs.
# The first example below recreates the folder structure and then # runs a separate 'rsync' for each file. rsync -aKxLPq -f"+ */" -f"- *" /archive/source/ /archive/target && (cd /archive/source && find . -mount -type f -print0 | xargs -0 -n1 -P8 -I% rsync -azPq % /archive/target/% ) # The example below works similar to the previous 'parallel' example: # it runs a separate 'rsync' for each subfolder under /archive/source # You can increase the '-maxdepth' argument to possibly get better performance # if either source or target (both) are NFS-mounted rsync -aKxLPq -f"+ */" -f"- *" /archive/source /archive/target && (cd /archive/source && find . -mindepth 1 -maxdepth 1 -mount -type d -print0 | xargs -0 -n1 -P8 -I% rsync -azPq % /archive/target/% )
pee
This utility allows you to pipe the output of one command as input for multiple other commands. The pee tool is better suited for this task than the similar and more commonly-available tee utility.
pee is like tee but for pipes. Each command is run and fed a copy of the standard input. The output of all commands is sent to stdout.
'pee' man page
Here’s a quick illustration:
echo "something anything" | pee "sed 's/some/any/g'" "sed 's/thing/one/g'" "sed 's/any/some/g'" anything anything someone anyone something something
But with a little more typing you can accomplish the same using tee:
echo "something anything" | tee >(sed 's/some/any/g') >(sed 's/thing/one/g') >(sed 's/any/some/g') 2&>/dev/null anything anything someone anyone something something
sponge
I actually use sponge quite a bit in my scripts. It is a great little tool that I particularly like when working with temporary files.
sponge reads standard input and writes it out to the specified file. Unlike a shell redirect, sponge soaks up all its input before writing the output file. This allows constructing pipelines that read from and write to the same file. sponge preserves the permissions of the output file if it already exists.
'sponge' man page
Let’s imagine we have an unsorted file called huge_list.txtand we need to sort it and save it. The usual approach would be something like this:
f=$(mktemp) && sort huge_list.txt > ${f} && /bin/mv ${f} huge_list.txt
This is tedious and not good for filesystem performance. With sponge you can really simplify the process:
sort huge_list.txt | sponge huge_list.txt
ts
This utility prepends each line of the previous command’s output with the current timestamp. It so happens that just a few days ago I wrote a script to monitor NFS performance and this script relies on ts to add timestamps to the collected data. You may find it interesting to see ts work its magic in an actual script.
ts adds a timestamp to the beginning of each line of input.
'ts' man page
But here’s a quick example:
ping -c2 google.com | grep --line-buffer bytes.*from | ts Sep 01 17:37:13 64 bytes from lga34s33-in-f14.1e100.net (142.250.80.14): icmp_seq=1 ttl=119 time=12.1 ms Sep 01 17:37:14 64 bytes from lga34s33-in-f14.1e100.net (142.250.80.14): icmp_seq=2 ttl=119 time=13.4 ms # You can also modify the time format to suit your needs. The syntax is the same as # you would use for the 'date' command ping -c2 google.com | grep --line-buffer bytes.*from | ts '%Y-%m-%d %H:%M:%S' 2021-09-01 17:38:10 64 bytes from lga25s70-in-f14.1e100.net (172.217.165.142): icmp_seq=1 ttl=119 time=12.1 ms 2021-09-01 17:38:11 64 bytes from lga25s70-in-f14.1e100.net (172.217.165.142): icmp_seq=2 ttl=119 time=13.3 ms
Alternatively, you achieve the same effect with more work by using GNU awk and date commands:
ping -c2 google.com | grep --line-buffer bytes.*from | awk '{ print strftime("%Y-%m-%d %H:%M:%S"), $0 }'
2021-09-01 17:46:08 64 bytes from lga25s77-in-f14.1e100.net (142.251.32.110): icmp_seq=1 ttl=118 time=7.33 ms
2021-09-01 17:46:09 64 bytes from lga25s77-in-f14.1e100.net (142.251.32.110): icmp_seq=2 ttl=118 time=8.46 ms
vidir
The vidir tool allows you to edit directory contents – such as delete and rename files and folders – inside a vitext editor. I find this tool to be particularly handy when used in conjunction with the find command.
vidir allows editing of the contents of a directory in a text editor. If no directory is specified, the current directory is edited.
'vidir' man page
Here’s a quick example:
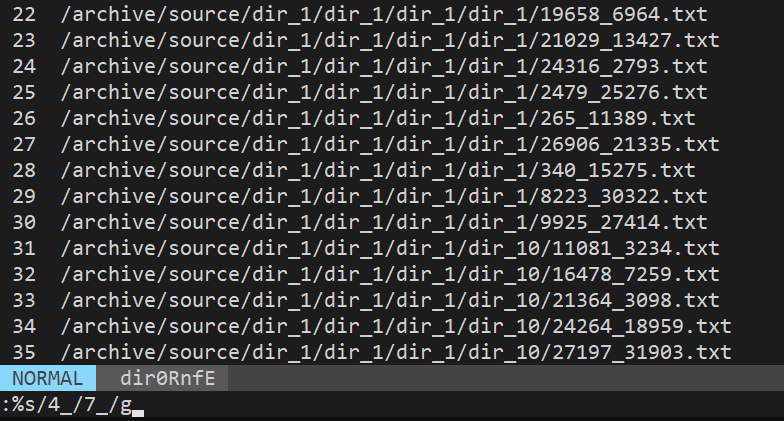
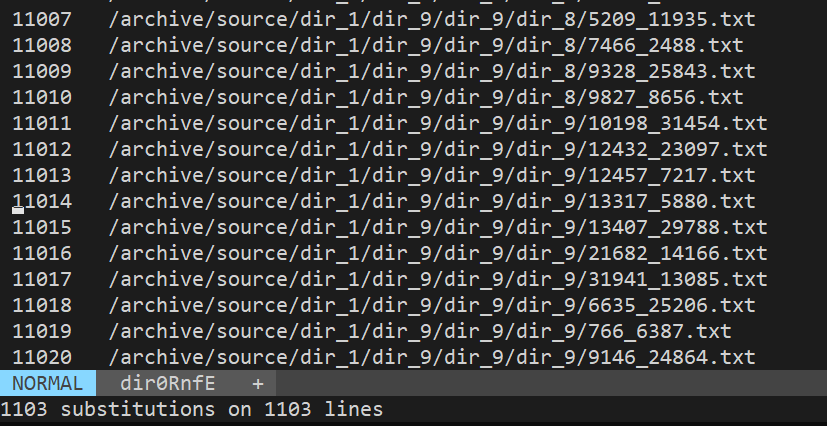
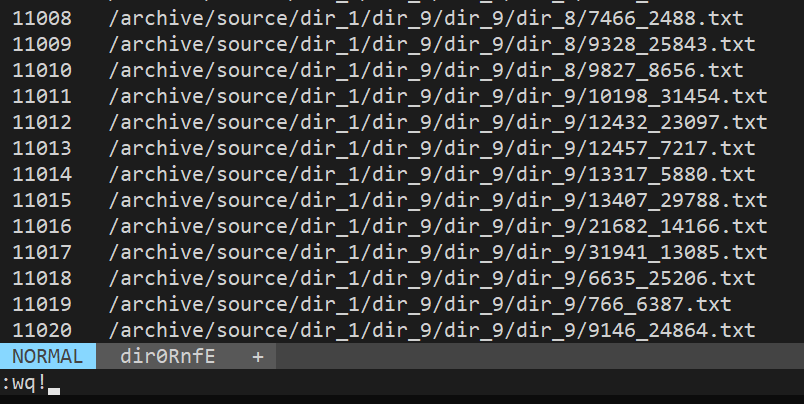
find /archive/source/dir_1 -type f | vidir -
This will open vi with the list of all the files. Now you can use vi to rename or delete files. In this example, I renamed all files containing string _4 in the filename to _7:
 |
 |
 |
Achieving the same result reliably using find and sed can be rather challenging.
vipe
This is definitely exotic and I can’t imagine a real-life scenario where this would be needed, but if you really have to edit the output of one command before piping it to the next one, the vipe utility is just what you need.
vipe allows you to run your editor in the middle of a unix pipeline and edit the data that is being piped between programs. Your editor will have the full data being piped from command1 loaded into it, and when you close it, that data will be piped into command2.
'vipe' man page
In the example below I run the date command, send the output to vi, add another line to the date that says “second line”, save the file, and then the while loop prints every line:
date | vipe $(mktemp) | while read line; do echo $line; done Wed Sep 1 18:18:07 EDT 2021 second line

Experienced Unix/Linux System Administrator with 20-year background in Systems Analysis, Problem Resolution and Engineering Application Support in a large distributed Unix and Windows server environment. Strong problem determination skills. Good knowledge of networking, remote diagnostic techniques, firewalls and network security. Extensive experience with engineering application and database servers, high-availability systems, high-performance computing clusters, and process automation.



{kind=link}